
Raisely is an online fundraising platform for ambitious charities across the world. We empower thousands of charities across the world to take control of their revenue and improve the wellbeing of people and our planet.
And why isn’t everyone shouting about Postgres full-text search?
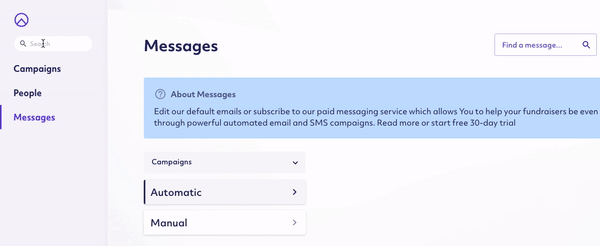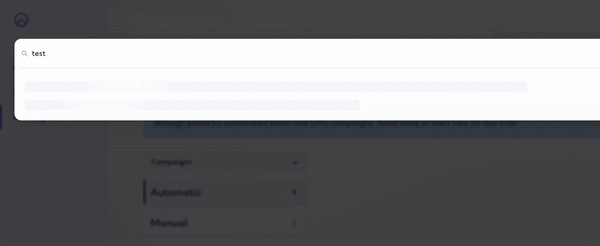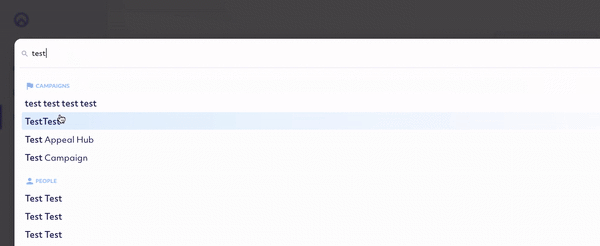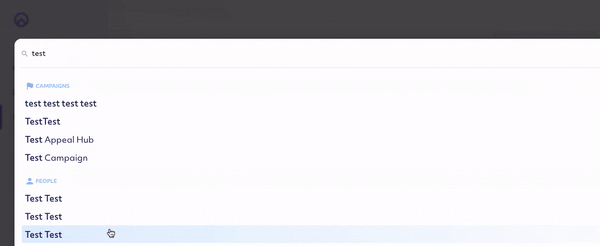
As we were kicking around ideas for the new Raisely admin panel at our staff retreat, Nick threw out this gem: “What if we had an ‘omnisearch’ at the top of the admin that returned any matching record of any type”.
This seemed like one of those ideas that fell squarely into the category of “Good idea, gonna take a lot of work to build”, but still worth doing a quick check on how hard it would be to get up quickly.
Having been burned before we were pretty reluctant to go down the path of trying to keep an Elasticsearch index in sync, and as a small team, we’re always trying to keep down the number of different technologies we have to maintain.
We started thinking maybe we could knock out a simple but good enough search using plain old SQL ilike against a few columns, but ranking results would be hard. A closer investigation of the Postgres docs revealed full-text search. (Why hadn’t I heard of this before???) It turns out Postgres has some amazing full text search built into it as standard.
A quick dive into those docs, and it became clear that Postgres (yet again) had everything we needed to get a nice feature up quickly.
Here’s how we got it up and running in one evening later that week.
First, a quick primer on how Postgres full-text search works.
Postgres Full-Text Search in a nutshell
In short, Postgres performs text searches by turning one or more columns into a “document”, in which Postgres tracks how many times each word occurs in the document. It uses dictionaries to normalize words so that a sentence like “That cat is a fat cat” would match a search for “cats”.
Then, in order to rank search results, Postgres takes the number of occurrences of matching words, along with a weighting to determine the best match.
Postgres has a bunch of text search functions to get that job done:
to_tsvector
To create a full-text search query, Postgres uses a vector of words and the number of times they appear in the text being searched. In our case, we used this together with `set weight' to assign a weight to each column.
setweight(to_tsvector(‘english’, coalesce(profiles.name, ‘’)), ‘A’) || setweight(to_tsvector(‘english’, coalesce(profiles.description, ‘’)), ‘B’)
For each column, I’m telling Postgres what language the column is in because it will group similar words together (eg jump, jumped, jumping). I’ve assigned a weight of ‘A’ to the name column, and ‘B’ for description, so matches in the name column are worth twice as much as matches in the description.
(We use coalesce to make sure that we always have a string, even if the column is null)
So now we have a document to search.
to_tsquery
To run a search on the vector, you compare a document it with a tsquery. The query has a specific context (eg english), and each word in the query must be joined by a logical operator.
to_tsquery(‘english’, ‘Bertha & cas:*’)
I’ve appended the last word in the query with a wildcard to allow us to do partial searches. The last word will match any word that starts with `cas`.
ts_rank_cd
To help us rank results, this function will generate a ranking for a vector against a query.
ts_rank_cd(<vector>, <query>)
ts_headline
Creates a highlighted snippet of the document so you can show the user why the search matched. Do note the warnings in the Postgres manual about performance, and make sure you’re only running this against the results you intend to display (not against the whole database).
ts_headline(name || ' ' || description, <query>)
After playing around with these in a SQL shell for about 10 mins I was amazed at how quickly we could get a full-text search going. So I built out some node code to test it.
function generateQuery(input) {
// Sanitise the search, remove all non-letters, numbers or periods
const illegalCharacters = XRegExp(‘[^\\p{L}\\s0–9\.]’, ‘g’);
const safeInput = input.replace(illegalCharacters, ‘’); // Join each word with &, put :* on the last word so it becomes
// a wildcard match
const queryString = safeInput.split(/\s/).join(‘ & ‘) + ‘:*’; return `to_tsquery(‘english’, ‘${queryString}’)`;
}/**
* @param {string[]} columns of the form <name>:<weight>
* @returns {string} search vector of weighted columns concatenated
* with ||
*/
function generateVector(columns) {
return columns.map((column) => {
let [colName, weight] = column.split(‘:’);
return `setweight(
to_tsvector(‘english’, coalesce(${colName},’’)),
‘${weight}’)`;
}).join(‘ || ‘);
}// Put it all together
function generateTSQuery(table, columns, search) {
const vector = generateVector(columns);
const query = generateQuery(search); return `SELECT uuid, ts_rank_cd(${vector}, ${query}) AS rank
FROM ${table}
WHERE (${vector}) @@ ${query}
ORDER BY rank DESC
LIMIT 10`;
}const query = generateTSQuery(
‘profiles’,
[‘name:A’, ‘description:B’],
‘Bertha Cus’
);console.log(query);
Indexes
Lastly, if we don’t want these searches to hang the database, we’ll need some indexes. Since the search is against the tsvector, not the columns themselves, the index needs to be over the vectors, not the columns.
The easy way to handle this is to have the index definition generate the vectors on the fly.
CREATE INDEX "profiles_full_text_index" USING GIN ((( setweight(to_tsvector('english'::regconfig, COALESCE(name, ''::character varying)::text), 'A'::"char")) || setweight(to_tsvector('english'::regconfig, COALESCE(description, ''::text)), 'B'::"char"))))
This comes with the advantage that Postgres will maintain the index for us but means that we can’t index over table joins, so if we wanted to do a full-text search over, say, profiles and the user that owns the profile, the index can’t be over all the columns.
In that case, we’d have to maintain a column containing the full-text search document for each record and index that column, which means we’d have to create triggers for updating the documents when a row is changed.
Stay in the loop. Delivered to your inbox twice a month.

Technical Lead at Raisely



